
스위프트 알고리즘 클럽 번역, 퀵 소트
퀵 소트
✔︎ 이 글은 Swift Algorighm Club 의 문서를 번역한 글입니다.
퀵 소트
목표: 오름차순 혹은 내림차순으로 배열을 정렬하기
퀵 소트는 역사에 남은 가장 유명한 알고리즘 중 하나이다. 아직 재귀에 대한 개념이 모호하던 1959년 Tony Hoare에 의해 고안되었다.
이해하기 쉽도록 Swift 코드로 구현해 보면 다음과 같다.
func quickSort<T: Comparable>(_ a: [T]) -> [T] {
guard a.count > 1 else { return a }
let pivot = a[a.count / 2]
let less = a.filter { $0 < pivot }
let equal = a.filter { $0 == pivot }
let greater = a.filter { $0 > pivot }
return quickSort(less) + equal + quickSort(greater)
}
배열이 주어지고, quickSort()는 이 배열을 pivot 변수에 기반해 세 부분으로 나눈다. 여기에서 pivot은 배열의 가운데 요소로 정해졌다(나중에 피벗을 정하는 다른 방법을 선택할 수 있다).
피벗보다 작은 요소들은 less 배열로 들어간다. 피벗과 같은 요소들은 equal 배열로 들어간다. 예상했듯, 피벗보다 큰 요소들은 모두 greater에 들어간다. 요소들을 <, ==, >로 비교하기 위해서 제네릭 타입의 T가 Comparable인 것이다.
배열이 세 등분 되었으면 quickSort()는 less와 greater 배열을 재귀적으로 정렬하고, 정렬된 하위 배열들(less, greater)과 equal 배열이 합쳐져 결과로 도출된다.
예시
[ 10, 0, 3, 9, 2, 14, 8, 27, 1, 5, 8, -1, 26 ]
이런 예시가 있다고 해 보자. 첫 번째로, 피벗 요소를 고른다. 8로 정했는데, 배열의 중앙에 위치하기 때문이다. 이를 기준으로 작고, 같고, 큰 부분으로 나눈다.
less: [ 0, 3, 2, 1, 5, -1 ]
equal: [ 8, 8 ]
greater: [ 10, 9, 14, 27, 26 ]
이는 잘 쪼개진 예시인데, less, greater가 같은 개수로 이루어져 있기 때문이다. 즉, 우리는 배열을 딱 반으로 나눌 수 있는 좋은 피벗을 고른 것이다.
여기서 less와 greater 배열이 아직 정렬되지 않았음을 확인하자. 이 두 하위 배열을 정렬하기 위해 quickSort()를 호출하는 것이다. 정확히 같은 일을 반복한다. 피벗을 뽑고, 최소 단위가 될 때까지 세 부분으로 쪼갠다.
less 배열을 통해 확인해보자.
[ 0, 3, 2, 1, 5, -1 ]
중간에 있는 1을 피벗으로 꼽는다(2로 해도 무방하다). 다시, 세 개의 하위 배열로 나눌 수 있다.
less: [ 0, -1 ]
equal: [ 1 ]
greater: [ 3, 2, 5 ]
아직 완벽히 끝나지 않았으니 less와 greater에 대해 quickSort()를 재귀적으로 호출한다. 다시 less를 보면,
[ 0, -1 ]
이고, -1을 피벗으로 뽑으면 다음과 같이 나뉘어진다.
less: [ ]
equal: [ -1 ]
greater: [ 0 ]
이제 -1보다 작은 요소가 없기 때문에 less 배열이 비게 된다. 다른 배열엔 하나의 요소들만 들어가 있다. 이는 이제 재귀의 끝에 도달했다는 것을 뜻하고, 다시 거슬러 올라가 greater 배열에 대해 같은 방식으로 쪼개진다.
greater 배열은 다음과 같았다.
[ 3, 2, 5 ]
2를 피벗으로 뽑아 하위 배열로 만들면 다음과 같은 결과가 나타난다.
less: [ ]
equal: [ 2 ]
greater: [ 3, 5 ]
결과를 보면 3을 피벗으로 뽑는 것이 더 나았을 것 같다. greater 배열이 완벽히 정렬될 때까지 재귀적으로 반복해야 하기 때문이다. 이는 좋은 피벗을 설정하는 것이 중요한 이유이다. 별로 안 좋은 피벗을 꼽으면, 퀵 소트는 엄청 느려진다.
less 배열과 마찬가지로 greater배열도 더이상 재귀를 반복할 수 없는 최소 단위일 때 함수 호출을 멈춘다. 이를 그림으로 보면 다음과 같다.
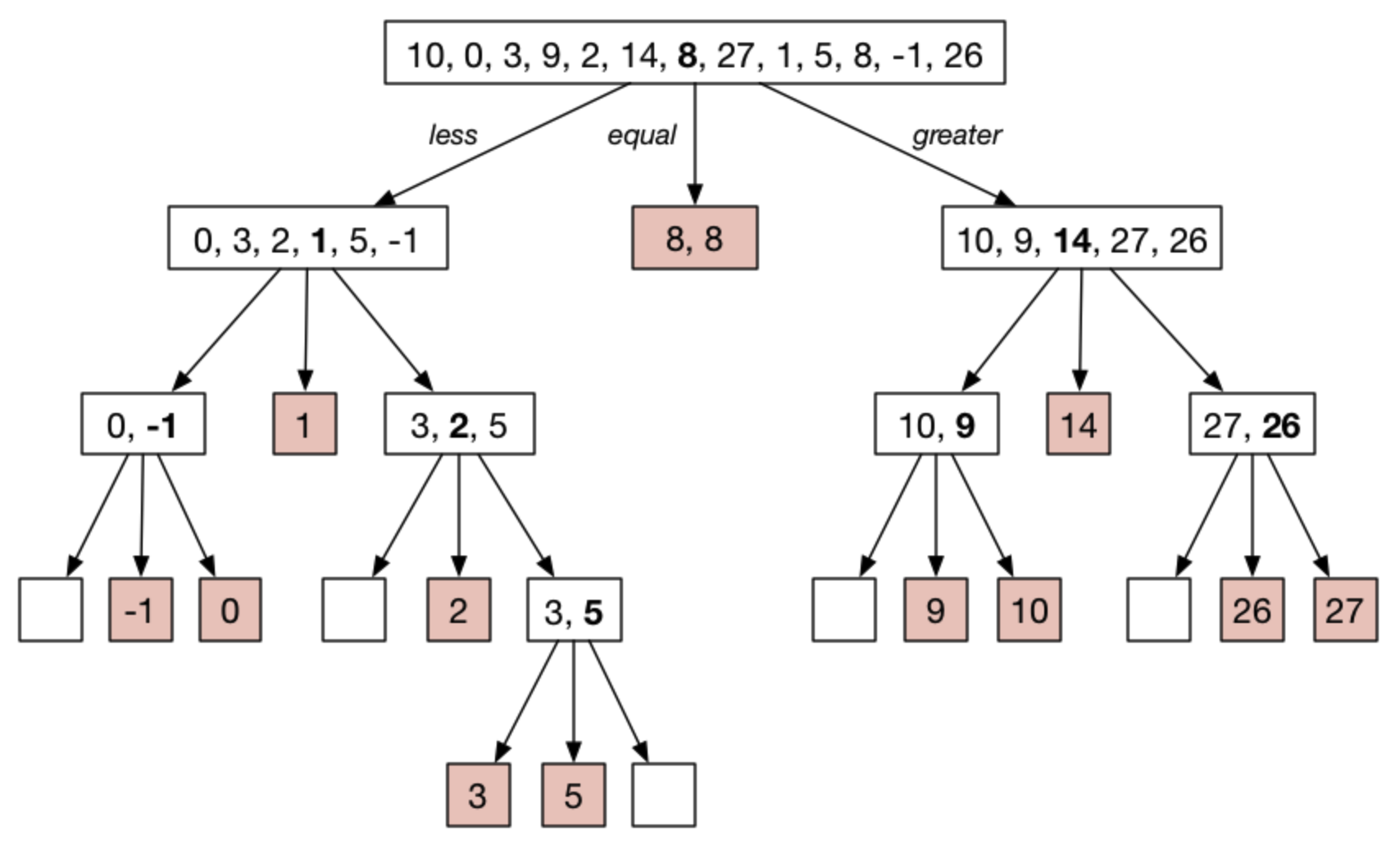
왼쪽부터 오른쪽으로 색칠된 부분을 보면 정렬된 배열을 얻을 수 있다.
[ -1, 0, 1, 2, 3, 5, 8, 8, 9, 10, 14, 26, 27 ]
여기서 8은 좋은 피벗인데, 정렬된 배열에서도 중앙에 위치하기 때문이다.
퀵소트가 어떻게 진행되는지에 대해 기본적인 원리를 이해할 수 있었길 바란다. 불행하게도, 이 버전의 퀵 소트는 filter()를 세 번이나 썼기 때문에 빠르지 않다. 배열을 나누는 더 좋은 방법들이 있다.
파티셔닝
배열을 피벗을 중심으로 나누는 것을 파티셔닝이라 하고, 여기엔 몇 가지 다른 파티셔닝 방법들이 있다.
[ 10, 0, 3, 9, 2, 14, 8, 27, 1, 5, 8, -1, 26 ]
배열이 다음과 같을 때, 중간에 위치한 요소 8을 피벗으로 정한 뒤 파티셔닝하면 다음과 같다.
[ 0, 3, 2, 1, 5, -1, 8, 8, 10, 9, 14, 27, 26 ]
----------------- -----------------
all elements < 8 all elements > 8
여기서 중요한 점은, 파티셔닝을 한 후 피벗이 되는 요소는 마지막으로 정렬될 위치에 미리 존재해야 한다는 것이다. 나머지 숫자들은 아직 정렬되지 않은 채 단순히 피벗을 기준으로 나뉘어졌을 뿐이다. 퀵 소트는 배열을 계속해서 파티셔닝해 모든 값들이 마지막 위치에(정렬된 위치에) 위치하도록 한다.
파티셔닝은 요소들이 매번 같은 순서로 분리되는 것을 보장하지 못하며, 8로 파티셔닝을 한 후 다음과 같이 분리될수도 있다.
[ 3, 0, 5, 2, -1, 1, 8, 8, 14, 26, 10, 27, 9 ]
딱 한가지 보장되는 것은 피벗을 기준으로 왼쪽은 작은 요소들, 오른쪽은 큰 요소들이 모여 있다는 점이다. 파티셔닝을 하다보면 배열이 본래의 순서가 바뀔 수 있기 때문에 퀵소트는 “안정된” 정렬기법(합병정렬과 다르게)이 아니다. 대부분의 경우 이는 큰 상관이 없다.
Lomuto의 파티셔닝
첫 번째로 보여 준 퀵 소트 예제에서 파티셔닝은 Swift의 filter()함수를 세 번 사용하는 것에 의해 이루어졌다. 이는 효율적이지 않다. 제자리에서 작동되는, 즉 원본의 배열을 수정하여 이루어지는 조금 더 똑똑한 파티셔닝 알고리즘에 대해 알아보자.
Lomuto의 파티셔닝을 스위프트 코드로 구현하면 다음과 같다.
func partitionLomuto<T: Comparable>(_ a: inout[T], low: Int, high: Int) -> Int {
let pivot = a[high]
var i = low
for j in low..<high {
if a[j] <= pivot {
a.swapAt(i, j)
i += 1
}
}
a.swapAt(i, high)
return i
}
이를 실행해볼 예시는 다음과 같다.
var list = [ 10, 0, 3, 9, 2, 14, 26, 27, 1, 5, 8, -1, 8 ]
let p = partitionLomuto(&list, low: 0, high: list.count - 1)
list // 결과 보기
여기서 list가 var로 선언되어있는 것에 주목하자. 이는 partitionLomuto()가 직접적으로 배열의 내용을 바꾸기 때문이다. (이를 위해서 inout 파라미터로 배열을 넘겨 준다.) 이는 새 배열을 할당하는 것보다 훨씬 효율적이다.
우리는 전체 배열을 계속해서 파티셔닝하는 대신, 한정된 범위를 더 작게 줄여나가며 파티셔닝해 퀵 소트를 사용하고 싶으므로 low, high 파라미터가 필요하다.
앞에선 배열의 중간에 있는 요소를 썼다면, Lomuto의 알고리즘에선 마지막 요소인 a[high]가 피벗이 된다는 게 중요하다. 지금까지의 예시에서 줄곧 8을 피벗으로 삼았기 때문에, 이번 예시에서도 8을 사용할 수 있도록 배열을 조작해놨다.
파티셔닝이 끝난 뒤 배열은 다음과 같이 변한다.
[ 0, 3, 2, 1, 5, 8, -1, 8, 9, 10, 14, 26, 27 ]
*
변수 p는 partitionLomuto()의 반환값을 저장하고, 여기서 p의 값은 7이다. 이것은 새로운 배열에서 피벗의 인덱스(별표 쳐진 위치)를 뜻한다.
왼쪽 파티션은 0부터 p-1까지이며, [0, 3, 2, 1, 5, 8, -1]이다. 오른쪽 파티션은 p+1부터 끝까지이며, [9, 10, 14, 26, 27](이 부분은 운 좋게 정렬이 됐다)이다.
여기서 흥미로운 점은, 8이 배열에서 한 번 이상 나온다는 것이다. 다른 8은 중간에 위치하지 않고, 왼쪽 파티션 어딘가에 속해있다. 이는 Lomuto 알고리즘이 가진 맹점으로, 중복된 요소가 많을수록 퀵 소트가 느려진다.
그럼 Lomuto 알고리즘이 실제로 어떻게 일어나는지 보자. 마법은 for 반복문에서 일어난다. 이 반복문은 배열을 네 개로 나눈다.
[ values <= pivot | values > pivot | not looked at yet | pivot ]
low i i+1 j-1 j high-1 high
a[low...i]: value <= pivot 인 값을 담는다.a[i+1...j-1]: value > pivot 인 값을 담는다.a[j...high-1]: 우린 아직 확인하지 못했다.a[high]: 피벗
반복문은 각 요소를 low에서부터 high-1까지 돌면서 모두 확인한다. 만약 현재 요소가 피벗보다 작거나 같으면 swap을 이용해 앞 부분으로 이동한다.
스위프트에서
(x, y) = (y, x)는x,y의 값을 교환할 수 있는 편리한 방법이다.swap(&x, &y)와 같이 쓸 수도 있다.
반복문이 끝나도 피벗은 여전히 배열의 맨 마지막에 위치해 있다. 그러므로 피벗보다 큰 첫 번째 요소와 바꾸어 준다. 이제 피벗은 <=와 >로 나뉜 사이에 존재하게 되고, 배열은 적절하게 파티셔닝된다.
예시를 하나씩 짚어보자.
[| 10, 0, 3, 9, 2, 14, 26, 27, 1, 5, 8, -1 | 8 ]
low high
i
j
처음엔 ‘아직 보지 않은’ 부분이 인덱스 0부터 11까지이다. 피벗은 인덱스 12에 위치해있다. ‘value <= pivot’과 ‘value > pivot’인 부분은 아직 아무 요소도 확인하지 않았기 때문에 비어있다.
첫 번째 요소인 10을 보자. 피벗보다 작은가? 아니므로 다음 요소로 넘어간다.
[| 10 | 0, 3, 9, 2, 14, 26, 27, 1, 5, 8, -1 | 8 ]
low high
i
j
이제 ‘아직 보지 않은’ 부분이 인덱스 1부터 11로 변화했고, ‘value > pivot’인 부분은 10을 포함하게 됐다. 역시 ‘value <= pivot’은 비어 있다.
두 번째 요소 0을 보자. 피벗보다 작은가? 그렇기 때문에 10과 0을 교환하고 i를 하나 올린다.
[ 0 | 10 | 3, 9, 2, 14, 26, 27, 1, 5, 8, -1 | 8 ]
low high
i
j
‘아직 보지 않은’ 부분이 인덱스 2부터 11로, ‘value > pivot’은 10을, ‘value <= pivot’은 0을 포함하게 됐다.
이 방법을 반복하다보면, 다음과 같은 배열을 얻게 된다.
[ 0, 3, 2, 1, 5, 8, -1 | 27, 9, 10, 14, 26 | 8 ]
low high
i j
마지막으로 a[i]와 a[high]를 바꾸어 피벗의 위치를 변경하는 것이다.
[ 0, 3, 2, 1, 5, 8, -1 | 8 | 9, 10, 14, 26, 27 ]
low high
i j
그리고 피벗의 인덱스인 i를 얻게 된다.
만약 아직 이 알고리즘이 명확히 이해되지 않으면, 플레이그라운드에서 어떻게 네 부분으로 나뉘는지 확인하는 것을 추천한다.
이 파티셔닝 방식을 퀵 소트에 적용하면 다음과 같다.
func quickSortLomuto<T: Comparable>(_ a: inout [T], low: Int, high: Int) {
if low < high {
let p = partitionLomuto(&a, low: low, high: high)
quickSortLomuto(&a, low: low, high: p - 1)
quickSortLomuto(&a, low: p + 1, high: high)
}
}
이제 엄청 간단해졌다. partitionLomuto()를 통해 피벗(항상 배열의 마지막에 위치한)을 중심으로 배열을 재정렬한다. 그리고 quickSortLomuto()를 재귀적으로 호출해 왼쪽과 오른쪽을 각각 정렬한다.
Lomuto의 알고리즘은 유일한 파티셔닝 방법은 아니지만, 가장 이해하기 쉽다. 교환 연산을 덜 사용하는 Hoare의 방법보다 효율적이진 않다.
Hoare의 파티셔닝
이 파티셔닝 방식은 퀵 소트를 만든 Hoare의 방법이다.
func partitionHoare<T: Comparable>(_ a: inout [T], low: Int, high: Int) -> Int {
let pivot = a[low]
var i = low - 1
var j = high + 1
while true {
repeat { j -= 1 } while a[j] > pivot
repeat { i += 1 } while a[i] < pivot
if i < j {
a.swapAt(i, j)
}
else {
return j
}
}
}
플레이그라운드에서 테스트할 수 있는 예시는 다음과 같다.
var list = [ 8, 0, 3, 9, 2, 14, 10, 27, 1, 5, 8, -1, 26 ]
let p = partitionHoare(&list, low: 0, high: list.count - 1)
list // 결과 보여줌
Hoare의 알고리즘에서 피벗은 언제나 첫 번째 요소, a[low]라는 점을 기억하자. 이번에도 역시 8을 피벗으로 사용한다.
결과는 다음과 같다
[ -1, 0, 3, 8, 2, 5, 1, 27, 10, 14, 9, 8, 26 ]
여기서는 피벗이 중간에 위치하지 않는다. Lomuto의 방법과는 달리, 반환하는 값이 꼭 새로운 배열의 피벗 인덱스여야 할 필요가 없기 때문이다.
대신에, 배열은 [low...p], [p+1...high]로 나누어져 있다. 여기서 p의 값은 6인데, 두 개의 파티션 [-1, 0, 3, 8, 2, 5, 1]과 [27, 10, 14, 9, 8, 26으로 나뉜 위치의 인덱스이다.
피벗은 파티션 중 하나 혹은 두개 이상에 포함돼있지만 알고리즘은 그 피벗이 어디에 위치해있는지 알려주지 않는다. 만약에 피벗이 한개 이상 존재한다면, 하나는 왼쪽에, 하나는 오른쪽에 위치할 수도 있다.
이런 차이점 때문에 Hoare의 퀵 소트는 약간 다르다.
func quickSortHoare<T: Comparable>(_ a: inout [T], low: Int, high: Int) {
if low < high {
let p = partitionHoare(&a, low: low, high: high)
quickSortHoare(&a, low: low, high: p)
quickSortHoare(&a, low: p + 1, high: high)
}
}
좋은 피벗 뽑기
Lomuto의 파티셔닝은 항상 배열의 마지막 요소를 피벗으로 지정한다. Hoare의 파티셔닝은 항상 첫번째 요소를 사용한다. 하지만 이 피벗들이 최선이라는 보장이 없다. 다음은 피벗으로 별로 좋지 않은 값을 뽑았을 때 일어나는 일이다.
[ 7, 6, 5, 4, 3, 2, 1 ]
배열이 다음과 같을 때, Lomuto의 파티셔닝을 사용한다고 가정하자. 피벗은 마지막 요소인 1이 된다. 피벗을 정한 후 우리는 다음과 같은 배열을 얻게 된다.
less than pivot: [ ]
equal to pivot: [ 1 ]
greater than pivot: [ 7, 6, 5, 4, 3, 2 ]
재귀적으로 큰 값들을 파티셔닝해보면 다음과 같은 하위 배열이 만들어진다.
less than pivot: [ ]
equal to pivot: [ 2 ]
greater than pivot: [ 7, 6, 5, 4, 3 ]
그리고 계속 이와 같이 쭉 반복된다.
이는 별로 좋지 않은데, 퀵 소트를 퀵 소트보다 한참 느린 삽입 정렬처럼 사용하고 있기 때문이다. 퀵 소트를 효과적으로 사용하기 위해선, 배열을 대충 반으로 나눌 수 있어야 한다.
위의 예시에서 최적의 피벗은 4이고, 이를 통해 다음과 같은 배열을 얻을 수 있다.
less than pivot: [ 3, 2, 1 ]
equal to pivot: [ 4 ]
greater than pivot: [ 7, 6, 5 ]
맨 처믕 혹은 맨 뒤 요소를 뽑는 대신 중간에 있는 요소를 뽑는 게 좋을 것 같다고 생각할 수 있지만, 다음과 같은 상황을 상상해보자.
[ 7, 6, 5, 1, 4, 3, 2 ]
중간에 있는 요소가 1이므로, 앞선 예시와 같이 비효율적인 방식으로 진행될 것이다.
이상적인 피벗은 파티셔닝할 배열의 중간값, 즉 정렬된 배열의 중간에 위치할 요소이다. 물론 이 중간값이 뭔지는 배열을 정렬하기 전까진 모르니 이 말이 닭과 달걀의 문제처럼 보일 지 모른다. 하지만, 이상적인 피벗은 아닐지라도 좋은 피벗을 고르는 약간의 트릭이 있다.
첫 번째 트릭은 “셋 중 중간값”을 고르는 것으로, 하위 배열에서 첫번째, 중간, 마지막 요소 중에서 중간값을 찾을 수 있다는 것이다. 이를 이용하면 종종 최적의 중간값을 얻을 수 있다.
다른 일반적인 방법은 피벗을 랜덤하게 뽑는 것이다. 가끔은 최적이 아닌 피벗을 고르지만, 평균적으로 이는 좋은 결과를 낸다. 랜덤으로 피벗을 골라 퀵 소트를 진행하는 예시는 다음과 같다.
func quickSortRandom<T: Comparable>(_ a: inout[T], low: Int, high: Int) {
if low < high {
let pivotIndex = random(min: low, max: high) // 1
(a[pivotIndex], a[high]) = (a[high], a[pivotIndex]) // 2
let p = partitionLomuto(&a, low: low, high: high)
quickSortRandom(&a, low: low, high: p - 1)
quickSortRandom(&a, low: p + 1, high: high)
}
}
여기엔 이전과 다른 두 중요한 차이점이 있다.
random(min:max:)함수는min...max범위 내에서,min,max를 포함하여 하나의 정수를 반환한다. 이것이pivotIndex가 된다.- Lomuto의 방법에선 맨 뒤의 값이 피벗의 시작이 되므로,
a[pivotIndex]와a[high]를 서로 교환해partitionLomuto()가 실행되기 전에 피벗을 배열의 맨 뒤로 보낸다.
정렬하는 데 랜덤한 숫자를 사용한다는 게 이상하게 들릴 지 모르지만, 퀵 소트를 모든 상황에서 효과적으로 사용하기 위해선 필수적이다. 안좋은 피벗을 사용하면 퀵 소트의 퍼포먼스가 O(n^2)와 같이 좀 끔찍하게 나올 수 있다. 하지만 랜덤한 숫자를 얻어오는 등과 같이 좋은 피벗을 고르게 된다면, 평균적으로 O(nlogn)의 퍼포먼스를 얻을 수 있으며, 이는 좋은 정렬 알고리즘이 얻는 실행 시간이다.
네덜란드 국기 파티셔닝
조금 더 좋게 만들 수 있다. 맨 처음 보여 준 퀵 소트 예시는 배열이 다음과 같이 파티셔닝 되어 있었다.
[ values < pivot | values equal to pivot | values > pivot ]
하지만 Lomuto의 방법을 봤듯이, 피벗이 하나 이상 있으면 왼쪽 절반에 중복되어 포함되는 것을 알 수 있다. Hoare의 방법에선 피벗이 어떤 곳이든 존재할 수 있음을 확인했다. 이에 대한 해결책은 ‘네덜란드 국기’ 파티셔닝으로, 네덜란드 국기가 세 개의 파티션으로 나뉘어져 있는 것에 착안해 이름이 붙여졌다.
이 방법에 대한 코드는 다음과 같다.
func partitionDutchFlag<T: Comparable>(_ a: inout [T], low: Int, high: Int, pivotIndex: Int) -> (Int, Int) {
let pivot = a[pivotIndex]
var smaller = low
var equal = low
var larger = high
while equal <= larger {
if a[equal] < pivot {
swap(&a, smaller, equal)
smaller += 1
equal += 1
}
else if a[equal] == pivot {
equal += 1
}
else {
swap(&a, equal, larger)
larger -= 1
}
}
return (smaller, larger)
}
이는 Lomuto의 방법과 비슷하게 흘러가는데, 네 개의 부분으로 쪼개진다는 것이 차이점이다.
[low...smaller-1]: value < pivot 인 값을 포함[smaller...equal-1]: value == pivot 인 값을 포함[equal...larger]: value > pivot 인 값을 포함[larger...high]: 아직 확인 안 함
여기서 피벗이 a[high]에 있다는 걸 보장하지 않는다. 대신에, 피벗으로 사용하고자 하는 요소의 인덱스를 넘겨준다.
var list = [ 10, 0, 3, 9, 2, 14, 8, 27, 1, 5, 8, -1, 26 ]
partitionDutchFlag(&list, low: 0, high: list.count - 1, pivotIndex: 10)
list // 결과 보여 줌
역시 8이 피벗이 되게금 하면, 다음과 같은 결과를 얻는다.
[ -1, 0, 3, 2, 5, 1, 8, 8, 27, 14, 9, 26, 10 ]
여기서 두 8들이 모두 중간에 있다는 것에 주목하자. partitionDutchFlag()의 반환값은 (6, 7) 튜플이다. 이는 피벗 요소를 포함하는 범위이다.
이를 퀵 소트에 이용하면 다음과 같다.
func quickSortDutchFlag<T: Comparable>(_ a: inout [T], low: Int, high: Int) {
if low < high {
let pivotIndex = random(min: low, max: high)
let (p, q) = partitionDutchFlag(&a, low: low, high: high, pivotIndex: pivotIndex)
quickSortDutchFlag(&a, low: low, high: p - 1)
quickSortDutchFlag(&a, low: q + 1, high: high)
}
}
네덜란드 국기 파티셔닝을 사용하면 중복된 요소들을 포함하는 배열에서 더욱 더 효율적으로 퀵 소트를 실행할 수 있다. (내가 네덜란드 사람이라 그런 건 아니고!)
partitionDutchFlag()을 구현할 때 사용했던swap()은 커스텀 코드로, 스위프트의swap()과 달리 두 요소가 같은 배열 요소를 참조할 때 에러를 반환하지 않는다. 이는 Quicksort.swift 에서 자세히 확인하자.

댓글남기기